
I didn’t expect to spend three months on one question: what happens to a sign language recognition model when you move the camera?
Turns out, everything breaks. But the way it breaks is actually pretty interesting.
The Idea #
For my Block C independent research project at Breda University of Applied Sciences, I wanted to investigate how camera viewing angle affects sign language recognition accuracy. I worked with Dutch Sign Language (NGT) fingerspelling, specifically the 22 static hand shapes used to spell out letters.
The experiment itself was simple: train a model on frontal images, then test it from 30° to the left and 30° to the right, and measure what happens. I had two hypotheses going in. First, that accuracy would drop when the camera moved away from the front. Second, that the left and right sides wouldn’t degrade the same way.
Building the Model #
Training a model from scratch on a small dataset is a recipe for overfitting, so instead I used a three phase transfer learning pipeline built on EfficientNet B0.
Phase 1 started from ImageNet weights, a massive general purpose image dataset, giving the model a strong foundation for understanding visual features like edges, textures, and shapes. Phase 2 fine tuned the model on around 87,000 ASL (American Sign Language) images, teaching it what hands forming letters look like. Phase 3 adapted it to NGT using a much smaller dataset I collected myself.
The idea behind transfer learning is that a model trained on one task can carry over useful knowledge to a related one. Going from ImageNet to ASL to NGT meant the model learned progressively more specific features, starting with general image understanding, then hand shape recognition, and finally the particular configurations used in Dutch Sign Language.
I collected around 2,750 images myself. Every letter, at three camera angles (frontal, 30° left, 30° right), with tape marks on the floor to keep positions geometrically consistent. The frontal images went to training, and all three angles were used for testing.
Below is what the NGT fingerspelling dataset looks like, one sample per letter from the frontal view:

The Domain Gap Discovery #
This is where the project took an unexpected turn.
My Phase 2 model was trained on clean, hand focused close up images at 300×300 pixels. But the test pipeline used MediaPipe, a hand detection library, to automatically locate and crop hands from upper body frames. Those crops came out at roughly 100×250 pixels, and when resized to 224×224 for the model, the stretching and interpolation made them look completely different.
Same hand, same letter, same angle. Yet the model scored around 20% on its own frontal test data. It wasn’t that it hadn’t learned the signs. The images just didn’t look like what it was trained on. That mismatch between training and test data, when the visual characteristics differ even though the actual content is the same, is called a domain gap.
The fix was to retrain Phase 2 using the MediaPipe crops directly. I split the 550 frontal crops into 13 training and 12 test images per letter, loaded the ASL checkpoint, and fine tuned again. Frontal accuracy climbed to 89.8%.
The training curves from the retrained model show it converging cleanly with no signs of overfitting:
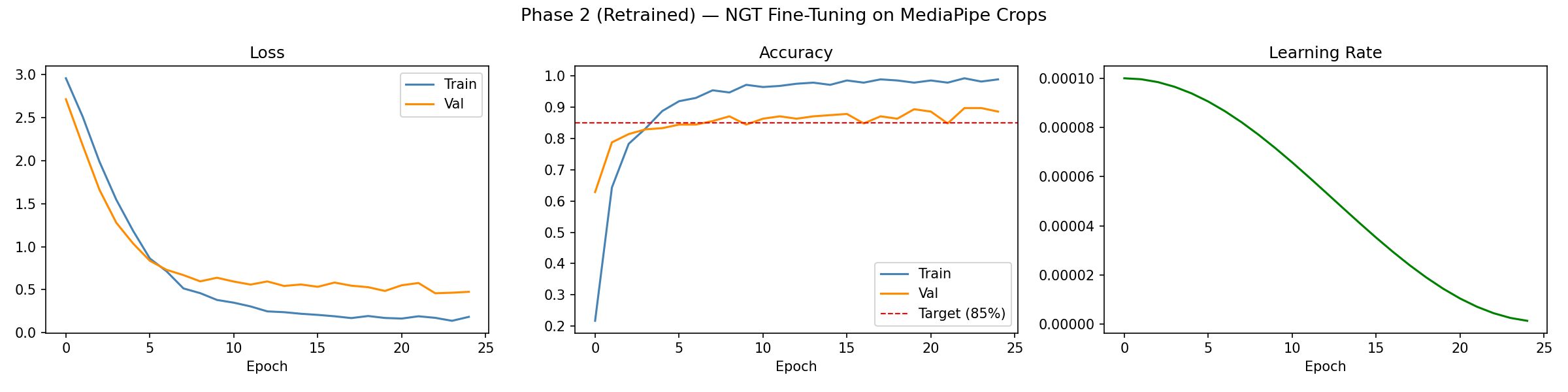
The lesson was clear. Your training and test data need to come from the same visual pipeline, not just depict the same subject.
The Results #
With the retrained model performing well on frontal images, I ran inference on all three test sets.
| Angle | Accuracy | Macro F1 |
|---|---|---|
| 0° (frontal) | 89.8% | 0.882 |
| −30° (left) | 36.0% | 0.274 |
| +30° (right) | 20.0% | 0.161 |
Moving the camera 30° to the left cuts accuracy by more than half. Moving it 30° to the right drops it to 20%, a 69.8 percentage point collapse. The model doesn’t degrade gradually. It falls off a cliff.
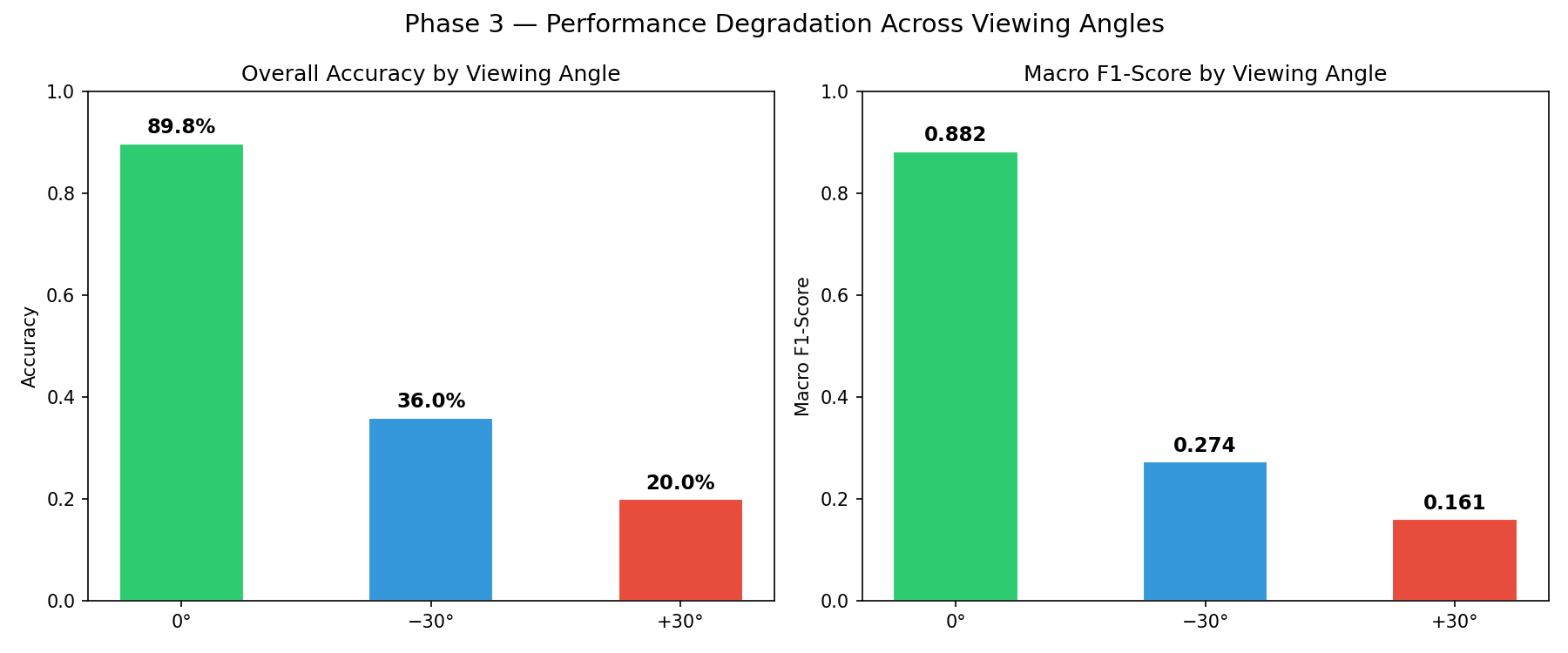
Both drops were statistically significant, confirmed through McNemar’s test with Bonferroni correction (α = 0.025). McNemar’s is a paired test that checks whether the pattern of correct and incorrect predictions changes significantly between two conditions. It fits here because the same letters are being classified under different viewing angles.
Why One Side Is Worse Than the Other #
One of the most interesting findings was the asymmetry between left and right. Both are 30° from frontal, yet the right side performs dramatically worse.
The explanation comes down to anatomy. I’m right handed, so all signs were performed with the right hand. From the +30° position (right side), the camera looks at the edge and back of the hand, the side with the least information about finger positions. From −30° (left side), the camera still captures most of the palm and finger configurations. The visual information the model needs to tell letters apart is simply more visible from one direction.
McNemar’s test confirmed the asymmetry was statistically significant (α = 0.05), and it showed up clearly in the numbers: 12 letters fell to 0% accuracy at +30°, compared to 7 at −30°.
What Survived and What Didn’t #
Not all letters responded the same way, and the pattern made physical sense.
The survivors: C maintained 100% accuracy across all three angles. Its shape, a curved open arc, looks distinctive from virtually any direction. G and P also held up relatively well. What these signs have in common is a strong overall silhouette that doesn’t depend on fine finger detail.
The casualties: F, N, and V all dropped from 100% frontal accuracy to 0% at both angles. These are signs that rely on precise finger positioning, extended fingers, specific spreads, subtle differences, things that become invisible or ambiguous from the side.
The heatmap below shows per class accuracy across all three angles. Green cells survived, red cells didn’t:
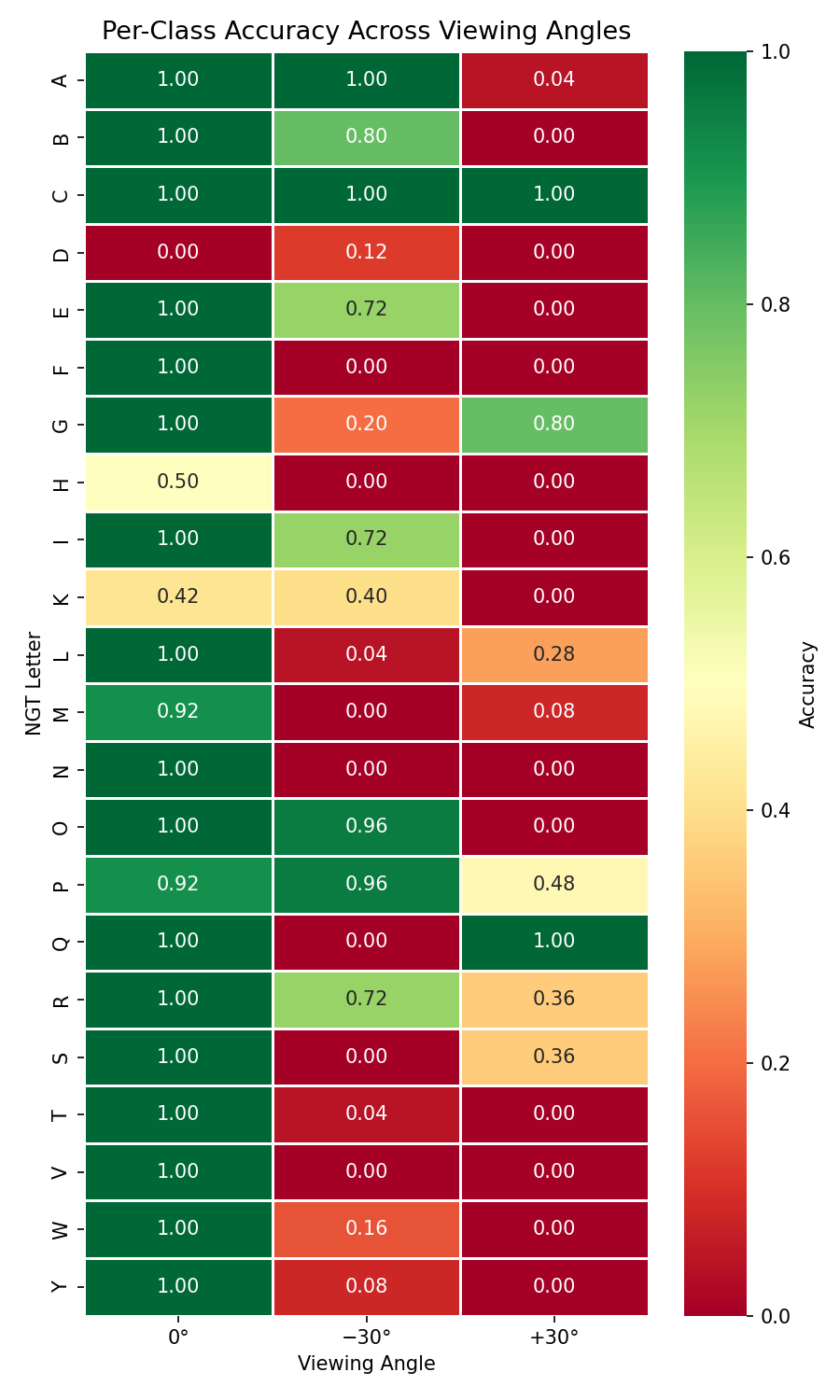
At angled views, the confusion matrices revealed the model collapsing toward a small set of “safe” guesses: B and O at −30°, C, Q, and S at +30°. Without enough finger detail, it was falling back on overall hand contour.
Confidence Tells Its Own Story #
Something else worth noting came from the model’s confidence scores. At frontal, correct predictions had a mean confidence of around 0.95, while incorrect ones sat at around 0.65, a clear separation. At angled views, that gap narrowed significantly, and the model started being confidently wrong more often.
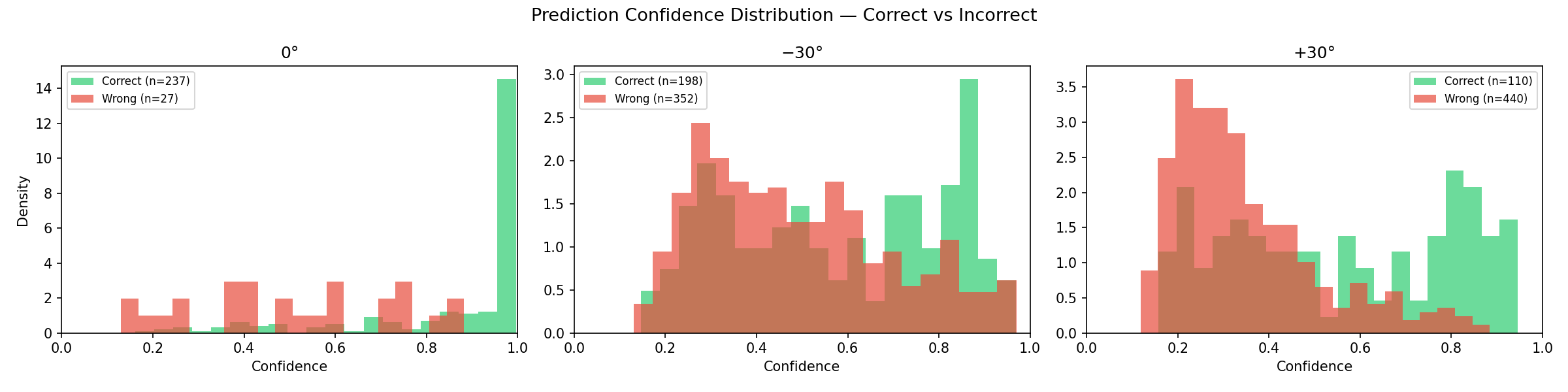
For deployment, this is a real problem. A confidence threshold that reliably filters bad predictions at frontal angles stops working at non frontal views.
What This Means #
The practical takeaway is that camera placement matters. A lot. A sign language recognition system trained on frontal data can’t just be deployed with an off angle camera and be expected to work. And the direction of the offset matters too: positioning the camera on the opposite side of the signer’s dominant hand preserves more of the useful visual information.
More broadly, the results highlight something that’s widely known but rarely quantified in computer vision: models trained from a single viewpoint don’t generalise to other viewpoints. Sign language is an especially clear case study for this, since meaning is carried entirely by hand shape, but the same principle applies to any visual recognition task where geometry changes with perspective.
Limitations and What’s Next #
The study has clear limitations. All data came from one right handed signer, so the asymmetry findings might reverse for someone who is left handed. Only ±30° was tested, so I can’t say whether the degradation is gradual or hits a sharp threshold somewhere. The training set was small (13 images per letter for the retrained Phase 2), and I only looked at static fingerspelling signs.
There’s a lot of room for future work. Testing at finer angle intervals (every 5° or 10°) would reveal the shape of the degradation curve. Collecting data from multiple signers would test whether the patterns generalise. It would also be interesting to see if including even a small number of angled images in training could meaningfully improve robustness, or if architectures like Vision Transformers handle viewpoint variation more gracefully than CNNs.
Wrapping Up #
What started as a controlled experiment about camera angles became a crash course in domain gaps, visual geometry, and the surprisingly fragile assumptions baked into image classification models. The model did exactly what it was trained to do: recognise hands from the front. It just had no idea what to do when the world looked different.
At least now I can confidently say that camera angles matter. The model still can’t confidently say much of anything, but we’re working on it.
This research was conducted as part of my Year 2 Block C project at Breda University of Applied Sciences, supervised by Myrthe Buckens.